|
Many RNAi screens are now-a-days performed to functionally annotate the mammalian genome. implementing a public repository based on common data standards is essential to realize the full value of large-scale RNAi data sets. Most of the available publications describing RNAi screen data focus on results from a few RNAi reagents per screen, typically those which are well-characterized experimentally from the main biological message. However, such articles rarely provide full 'hit lists' of reagents that scored positive in the primary screen, partly because no database of record has been established and widely accepted as a repository for large-scale mammalian RNAi data. Envision of an open-access public repository that includes raw and annotated mammalian RNAi results, well-documented experimental and data analysis protocols, and the sequences of RNAi reagent has become a necessity of time. This would allow inclusion of information that validates specific RNAi reagents; critical data on the impact of RNAi on gene and protein expression that are usually collected on a smaller scale. Such a repository would be a valuable community source that can be used for effective data mining. Bioinformatics analysis of aggregated RNAi data sets may contribute important information to the overall functional annotation of genomes. To develop mammalian RNAi data repository, there are three important challenges that much be addressed first -
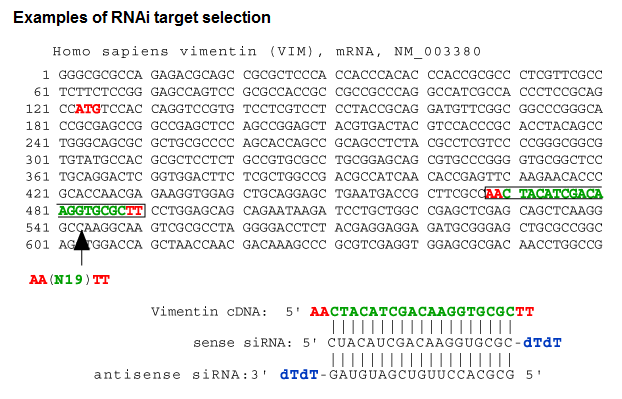
Data standards and formats for describing large data sets are being developed simultaneously by many groups. The MIARE (Minimum Information About an RNAi experiment) and MIACA (Minimum Information about a Cellular Assay) guidelines are relevant for describing RNAi data are recognized as part of the larger minimum information standards effort. The wealth of data accumulating from RNAi screens should not be hidden in supplementary information, but rather made accessible in public data repositories to contribute meaningfully to our understanding of biology [47]. RNAi at National Center for Biotechnology Information (NCBI) Before picking siRNA target on the gene of interest, its mRNA sequence has to be obtained from the nucleic acid database or the sequence accession number as some siRNA design tools can take accession number as input. Use of gene's RefSeq from NCBI is recommanded. The siRNA targets on the mRNA sequence of a gene should not share significant homology with the other genes or sequences in the genome, therefore, homology search is essential for preventing off-target effects. Although most siRNA design tools provide BLAST search option, direct use NCBI's BLAST tool can also be done [55]. Consider the following example for target gene selection using RNAi by above protocol [57]...
Downloads | Glossary | References | Contact © 2012, Saie Mogre. All Rights Reserved. |